
Minimax, Alpha-Beta, and Expectimax
Multi-agent search in Pacman. Minimax with depth-limited game trees, alpha-beta pruning, expectimax for random ghosts, and evaluation functions.
Abstract#
Second assignment in the Berkeley Pacman series. This time Pacman has to deal with ghosts that are actively trying to eat him. The assignment walks through minimax search with multiple adversaries, alpha-beta pruning, expectimax for modeling random ghosts, and writing evaluation functions that balance food, ghost distance, and scared time. Most of the work is recursive tree traversal with careful bookkeeping of agent indices and depth.
The setup is the same Pacman framework from the search assignment. The difference is that now there are ghosts, and your code controls Pacman’s decision-making against them. You implement everything in multiAgents.py.

All code below is Python 2, variable names left as-is.
Reflex agent#
The first question is a warm-up: write an evaluation function for a reflex agent that only looks one step ahead. Given the current state and a proposed action, return a score for how good the resulting state is.
def evaluationFunction(self, currentGameState, action):
successorGameState = currentGameState.generatePacmanSuccessor(action)
newPos = successorGameState.getPacmanPosition()
newFood = successorGameState.getFood()
newGhostStates = successorGameState.getGhostStates()
newScaredTimes = [ghostState.scaredTimer for ghostState in newGhostStates]
actual_score = successorGameState.getScore()
nearest_ghost_pos=newGhostStates[0].getPosition()
nearest_ghost = manhattanDistance(newPos, nearest_ghost_pos)
scared_time=newScaredTimes[0]
if nearest_ghost > 0:
if scared_time>0:
actual_score = actual_score+(20/nearest_ghost)
else:
actual_score = actual_score-(10/nearest_ghost)
newFood_positions=newFood.asList()
if len(newFood_positions)!=0:
nearest_food = manhattanDistance(newPos, newFood_positions[0])
for food in newFood_positions:
temp_food = manhattanDistance(newPos, food)
if temp_food<nearest_food:
nearest_food = temp_food
actual_score = actual_score + (10/nearest_food)
return actual_scoreThree things go into the score on top of the game’s own score:
- Ghost distance: if the ghost is scared, add (move toward it). If it’s not scared, subtract (run away). Inverse distance so the effect is stronger when the ghost is close.
- Food distance: add for the nearest food pellet. Pulls Pacman toward food.
- Only looks at the first ghost (
newGhostStates[0]), which is a simplification. With multiple ghosts you’d want to check all of them.
The weights (10, 20) were trial and error. They worked well enough on the test layouts.
Minimax#
Minimax models the game as a tree where Pacman (the maximizer) and the ghosts (minimizers) alternate turns. You search to a fixed depth and evaluate the leaves with an evaluation function.
The Pacman framework has multiple ghosts, so within each “ply” you cycle through Pacman (agent 0), then ghost 1, ghost 2, etc. When you’ve gone through all agents, the depth increments by 1.
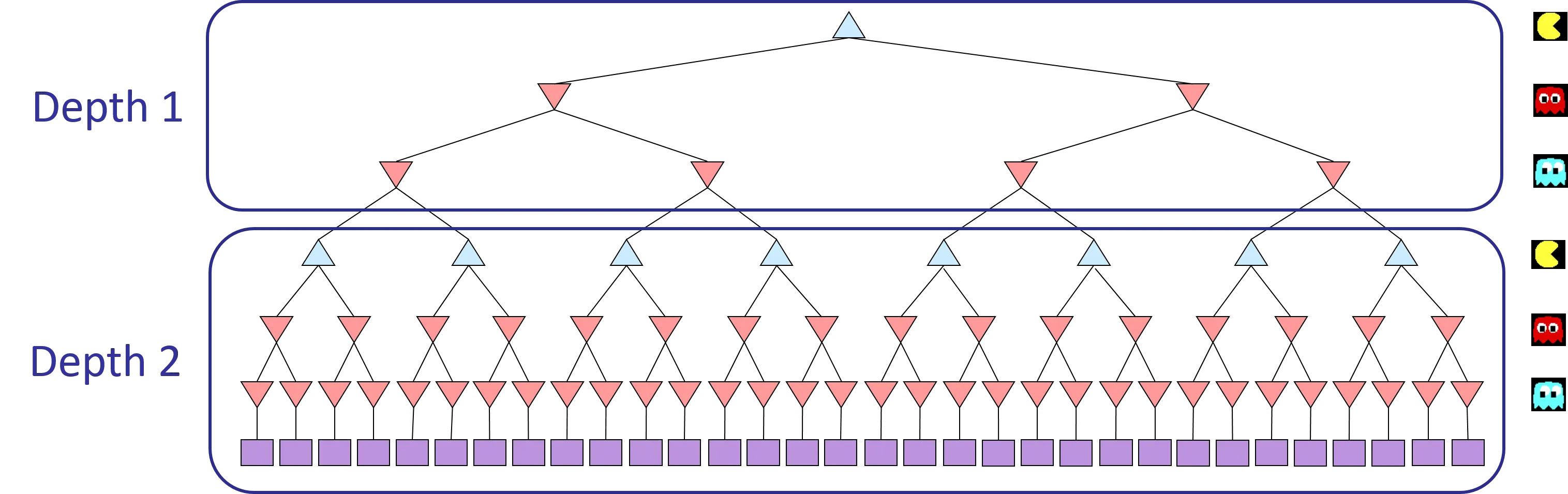
def getAction(self, gameState):
def checkTerminal(state,agent,depth):
return state.isWin() or state.isLose() or (state.getLegalActions(agent)==0) or (depth==self.depth)
def minimax(stateValues):
state=stateValues[0]
agent=stateValues[1]
depth=stateValues[2]
if agent==state.getNumAgents():
depth=depth+1
return minimax((state,0,depth))
if checkTerminal(state,agent,depth):
return self.evaluationFunction(state)
children_nodes = []
legalActions = state.getLegalActions(agent)
for action in legalActions:
temp=minimax((state.generateSuccessor(agent, action),agent+1,depth))
children_nodes.append(temp)
if agent % state.getNumAgents()!=0:
return min(children_nodes)
return max(children_nodes)
legalActions = gameState.getLegalActions(0)
max_utility,max_index = float('-inf'),0
for index,action in enumerate(legalActions):
temp_utility = minimax((gameState.generateSuccessor(0, action), 1, 0))
if temp_utility>max_utility:
max_utility = temp_utility
max_index = index
return legalActions[max_index]I used a single recursive function for both max and min layers. The agent index determines which role it plays: agent 0 is max, everything else is min. When the agent index wraps around past getNumAgents(), it resets to 0 and bumps the depth.
The root level is separate because you need to recover the actual action, not just the utility value. It iterates over Pacman’s legal actions, evaluates each successor tree, and picks the one with the highest utility.
Alpha-beta pruning#
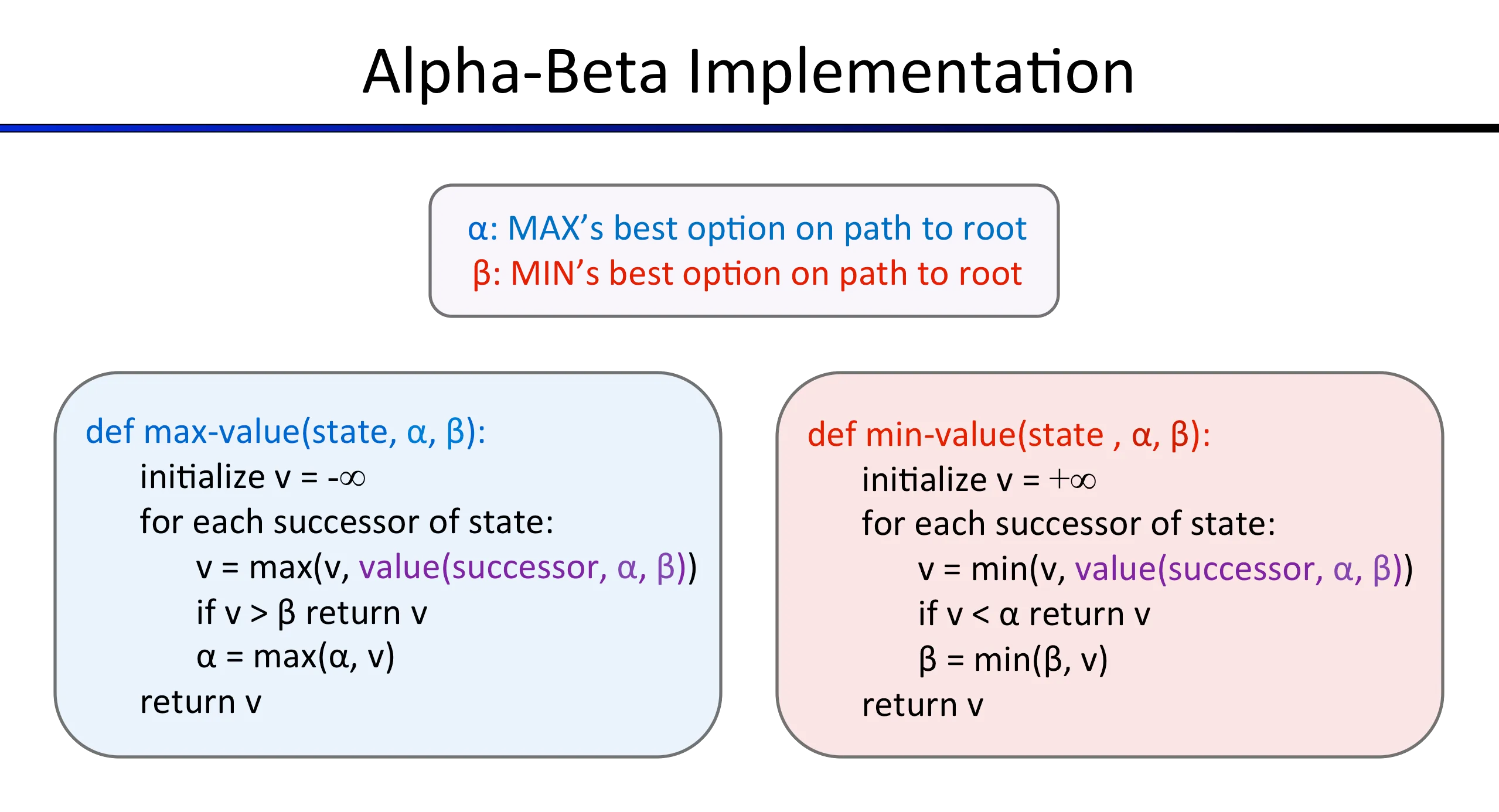
Alpha-beta is minimax with pruning. You keep track of two bounds:
- : the best value the maximizer can guarantee so far
- : the best value the minimizer can guarantee so far
If at any point the minimizer finds a value below , the maximizer will never let the game reach this branch, so you prune. Same logic in reverse for the maximizer and .
def getAction(self, gameState):
def checkTerminal(state,agent,depth):
return state.isWin() or state.isLose() or (state.getLegalActions(agent)==0) or (depth==self.depth)
def alphaBetaPruning(stateValues,alpha,beta):
state=stateValues[0]
agent=stateValues[1]
depth=stateValues[2]
best_action=None
if agent == state.getNumAgents():
agent = 0
depth = depth + 1
if checkTerminal(state,agent,depth):
return [self.evaluationFunction(state),best_action]
else:
if agent % state.getNumAgents()==0:
return maxValue((state,agent,depth), alpha, beta)
else:
return minValue((state,agent,depth), alpha, beta)
def minValue(stateValues,alpha,beta):
v=float('inf')
state=stateValues[0]
agent=stateValues[1]
depth=stateValues[2]
best_action= None
for action in state.getLegalActions(agent):
successor = state.generateSuccessor(agent, action)
value,_ = alphaBetaPruning((successor, agent + 1,depth), alpha, beta)
v,best_action = min((v, best_action), (value, action))
if agent % state.getNumAgents()==0:
if v > beta:
return v,best_action
alpha = min(alpha,v)
else:
if v < alpha:
return v,best_action
beta = min(beta,v)
return [v,best_action]
def maxValue(stateValues,alpha,beta):
v=float('-inf')
state=stateValues[0]
agent=stateValues[1]
depth=stateValues[2]
best_action = None
for action in state.getLegalActions(agent):
successor = state.generateSuccessor(agent, action)
value,_ = alphaBetaPruning((successor, agent + 1, depth),alpha, beta)
v,best_action = max((v, best_action), (value, action))
if agent % state.getNumAgents()==0:
if v > beta:
return v,best_action
alpha = max(alpha,v)
else:
if v < alpha:
return v,best_action
beta = max(beta,v)
return [v,best_action]
alpha=float('-inf')
beta=float('inf')
_,best_action = alphaBetaPruning((gameState,0,0),alpha,beta)
return best_actionThis version uses three functions instead of one: a dispatcher (alphaBetaPruning), maxValue for Pacman, and minValue for ghosts. The dispatcher handles the agent wrapping and terminal check, then routes to the appropriate function.
The functions return [value, best_action] tuples so the root call can extract the action directly. The _ in value, _ = alphaBetaPruning(...) discards the action at intermediate levels where you only care about the value.
One thing: both minValue and maxValue have a conditional branch checking whether the agent is Pacman or a ghost. In practice maxValue is only called for Pacman and minValue only for ghosts, so only one branch in each function actually executes. The conditional is redundant but harmless.
Expectimax#
Expectimax replaces the ghosts’ min with an average. Instead of assuming ghosts play optimally (minimizing your score), you assume they pick actions uniformly at random. This is more realistic for the Pacman ghosts, which don’t actually play minimax.
def getAction(self, gameState):
def checkTerminal(state,agent,depth):
return state.isWin() or state.isLose() or (state.getLegalActions(agent)==0) or (depth==self.depth)
def expectiMax(stateValues):
state=stateValues[0]
agent=stateValues[1]
depth=stateValues[2]
if agent == state.getNumAgents():
depth=depth + 1
return expectiMax((state, 0,depth))
if checkTerminal(state,agent,depth):
return self.evaluationFunction(state)
children_nodes = []
for action in state.getLegalActions(agent):
children_nodes.append(expectiMax((state.generateSuccessor(agent, action), agent + 1,depth)))
if agent % state.getNumAgents() == 0:
return max(children_nodes)
else:
return sum(children_nodes)*1.0/len(children_nodes)
legalActions = gameState.getLegalActions(0)
max_utility = float('-inf')
max_index = 0
for index, action in enumerate(legalActions):
temp_utility = expectiMax((gameState.generateSuccessor(0, action), 1, 0))
if temp_utility > max_utility:
max_utility = temp_utility
max_index = index
return gameState.getLegalActions()[max_index]The structure is the same as minimax. The only change is in the ghost layers:
return sum(children_nodes)*1.0/len(children_nodes)instead of min(children_nodes). The *1.0 is a Python 2 thing to force float division.
Expectimax can’t use alpha-beta pruning because you need all children to compute the average. With minimax you can prune branches that provably won’t affect the result. With expectimax every child contributes to the expected value.
Better evaluation function#
The last question asks for an evaluation function that works on the current state (not a state-action pair like the reflex agent). This one evaluates how good a game state is for Pacman.
def betterEvaluationFunction(currentGameState):
newPos = currentGameState.getPacmanPosition()
newFood = currentGameState.getFood()
newGhostStates = currentGameState.getGhostStates()
newScaredTimes = [ghostState.scaredTimer for ghostState in newGhostStates]
pred_score = currentGameState.getScore()
nearest_ghost_distance = manhattanDistance(newPos, newGhostStates[0].getPosition())
def countSurroundingFood(newPos, newFood):
count = 0
for x in range(newPos[0]-3, newPos[0]+4):
for y in range(newPos[1]-3, newPos[1]+4):
if x>=0 and y>=0 and (x < len(list(newFood)) and y < len(list(newFood[1]))):
if newFood[x][y]:
count += 1
return count
def distanceToNearestFood(newPos,newFood):
if(len(newFood.asList())):
nearest_food = manhattanDistance(newPos, newFood.asList()[0])
for food in newFood.asList():
temp_food = manhattanDistance(newPos, food)
if temp_food<nearest_food:
nearest_food = temp_food
return nearest_food
else:
return 0
total_surrounding_food_count=countSurroundingFood(newPos,newFood)
pred_score = pred_score + total_surrounding_food_count
if nearest_ghost_distance > 0:
if newScaredTimes[0]>0:
pred_score = pred_score+(100/nearest_ghost_distance)
else:
pred_score = pred_score-(10/nearest_ghost_distance)
distance_to_nearest_food=distanceToNearestFood(newPos,newFood)
if distance_to_nearest_food!=0:
pred_score = pred_score + (10/distance_to_nearest_food)
return pred_scoreThree features on top of the game score:
-
Surrounding food count: how many food pellets are within a 7x7 grid centered on Pacman (Manhattan radius of 3). Added directly to the score. This rewards being in food-dense areas, not just being close to one pellet.
-
Ghost distance: same inverse-distance logic as the reflex agent, but the scared ghost weight is much higher ( vs ). If a ghost is scared and nearby, Pacman should chase it aggressively because eating a ghost is worth 200 points.
-
Nearest food: for the closest food pellet.
The surrounding food count is what makes this better than the reflex evaluation. The reflex version only knows about the nearest food. This one knows about the local food density, so Pacman gravitates toward clusters of food rather than chasing individual pellets.