
Value Iteration and Q-Learning
MDPs, Bellman equations, batch value iteration, tabular Q-learning with epsilon-greedy exploration, and approximate Q-learning with feature weights.
Abstract#
Third Pacman assignment, now on reinforcement learning. The first half is value iteration on a known MDP (Gridworld), where you have the transition model and can compute optimal values directly. The second half is Q-learning, where the agent learns from experience without knowing the transition model. There’s also a section on tuning discount, noise, and living reward parameters to steer an agent’s policy on a bridge-crossing grid. I found the parameter tuning problems surprisingly tricky because the interactions between discount, noise, and living reward are not obvious until you work through specific cases.
The framework for this assignment is Gridworld: a grid where the agent moves in cardinal directions, some cells are walls, some are terminal states with rewards, and transitions can be stochastic (with some probability you move in a direction you didn’t intend). The agent code goes in valueIterationAgents.py, qlearningAgents.py, and analysis.py.
All code is Python 2, variable names as-is.
Value iteration#
Value iteration computes the optimal value function by repeatedly applying the Bellman update:
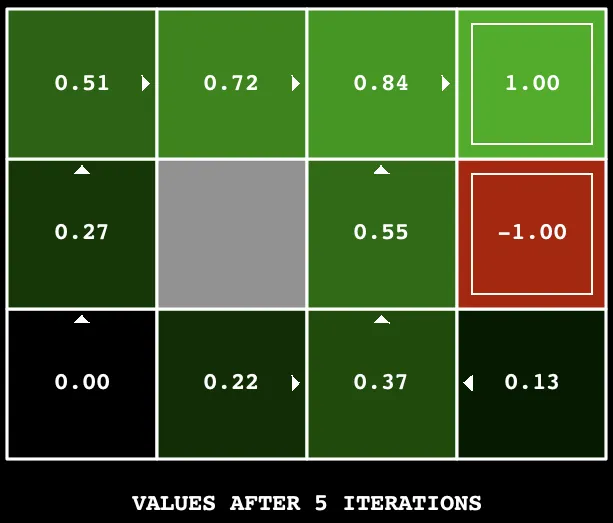
where is the transition model, is the reward, and is the discount factor. After enough iterations, converges to .
def __init__(self, mdp, discount = 0.9, iterations = 100):
self.mdp = mdp
self.discount = discount
self.iterations = iterations
self.values = util.Counter()
for _ in range(iterations):
updatedValues=self.values.copy()
for state in self.mdp.getStates():
if self.mdp.isTerminal(state):
pass
else:
actions=self.mdp.getPossibleActions(state)
values=[]
for action in actions:
values.append(self.getQValue(state, action))
updatedValues[state]=max(values)
self.values=updatedValuesThe important thing is the batch update: you copy the entire value table at the start of each iteration, compute new values using the old copy, and swap the whole table at the end. If you updated values in-place, the order you iterate through states would affect the result. With batch updates it doesn’t matter.
Terminal states keep their default value of 0 (the pass branch). util.Counter defaults to 0 for any key you haven’t set, so terminal states don’t need special initialization.
Q-value computation#
The Q-value for a state-action pair is the expected utility of taking that action and then following the optimal policy:
def computeQValueFromValues(self, state, action):
qValue=0
for nextState,prob in self.mdp.getTransitionStatesAndProbs(state,action):
reward=self.mdp.getReward(state, action, nextState)
qValue += prob * (reward + (self.discount * self.values[nextState]))
return qValueThis iterates over all (nextState, probability) pairs from the transition model and accumulates . The policy extraction is then just argmax over actions:
def computeActionFromValues(self, state):
policies = util.Counter()
for action in self.mdp.getPossibleActions(state):
policies[action] = self.getQValue(state, action)
return policies.argMax()Parameter tuning#
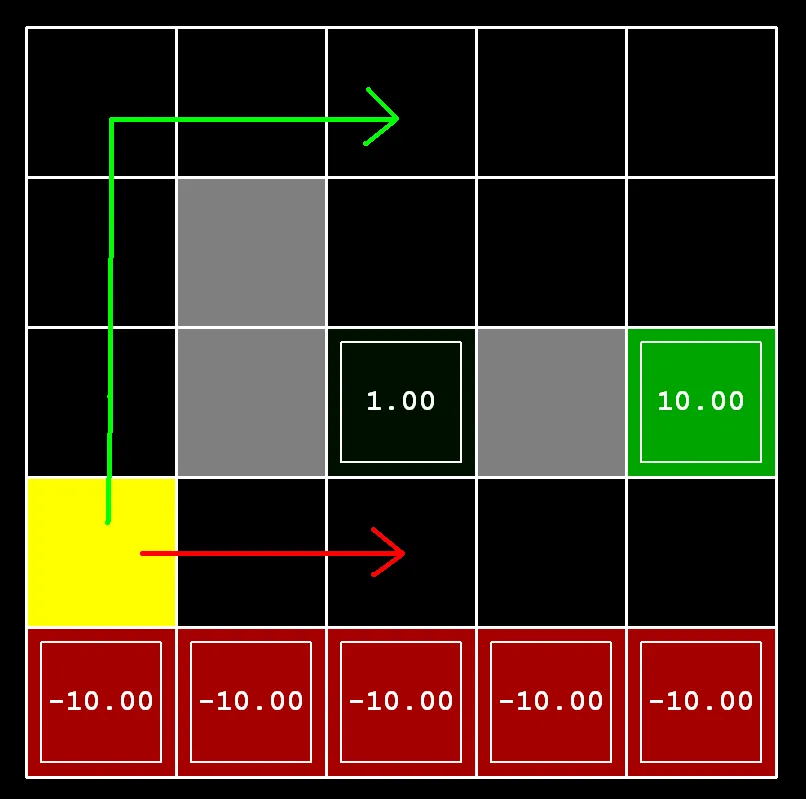
A set of questions asked you to find specific combinations of discount, noise, and living reward that produce particular policies on a bridge-crossing grid. The grid has a narrow bridge over a cliff: walking across the bridge risks falling off (if noise > 0), but reaches a high-reward terminal state on the other side. There’s also a low-reward exit nearby.

def question2():
answerDiscount = 0.9
answerNoise = 0.0
return answerDiscount, answerNoiseSetting noise to 0 makes transitions deterministic. The agent will cross the bridge because there’s no risk of falling off. With any noise, the bridge is dangerous because a random sideways step means death.
The other questions asked for policies like “prefer the close exit, risk the cliff” or “prefer the distant exit, avoid the cliff.” Each one requires reasoning about how the three parameters interact:
def question3a(): # close exit, risk cliff
answerDiscount = 0.1
answerNoise = 0.0
answerLivingReward = 0.6
return answerDiscount, answerNoise, answerLivingReward
def question3b(): # close exit, avoid cliff
answerDiscount = 0.1
answerNoise = 0.1
answerLivingReward = 0.6
return answerDiscount, answerNoise, answerLivingReward
def question3c(): # distant exit, risk cliff
answerDiscount = 0.6
answerNoise = 0.0
answerLivingReward = 0.6
return answerDiscount, answerNoise, answerLivingReward
def question3d(): # distant exit, avoid cliff
answerDiscount = 0.8
answerNoise = 0.2
answerLivingReward = 0.5
return answerDiscount, answerNoise, answerLivingReward
def question3e(): # avoid all exits, never terminate
answerDiscount = 0.0
answerNoise = 0.0
answerLivingReward = 0.0
return answerDiscount, answerNoise, answerLivingRewardThe logic for each:
- 3a: Low discount makes the distant +10 exit nearly worthless, so the agent goes for the nearby +1. No noise means the cliff is safe to walk next to.
- 3b: Same low discount to prefer the close exit. Adding noise makes the cliff dangerous, so the agent takes the longer path around.
- 3c: Higher discount makes the +10 exit worth pursuing. No noise, so the cliff path is safe.
- 3d: High discount for the distant exit. Noise makes the cliff dangerous, so the agent goes the long way around.
- 3e: Discount 0 means all future rewards are worth nothing. Living reward 0 means there’s no cost or benefit to staying alive. The agent has no reason to go anywhere.
These were solved by trying values and watching the policy visualization. There’s no formula, just reasoning about what each parameter does and then verifying.
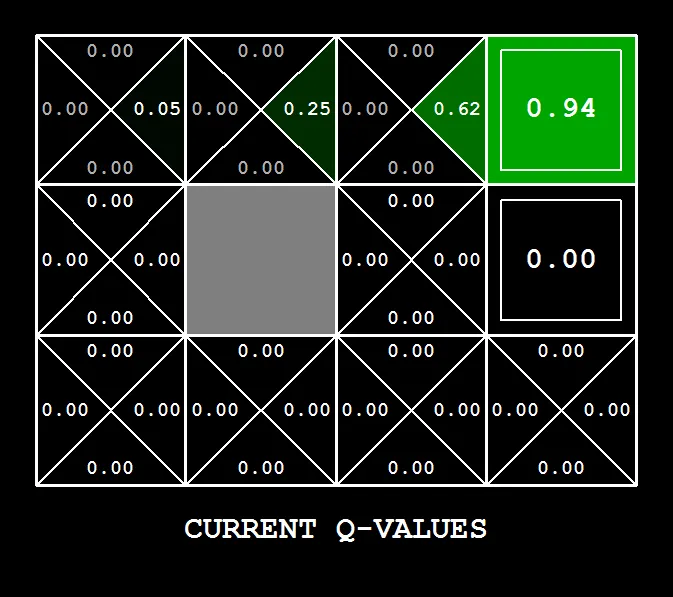
Q-learning#
Value iteration requires knowing the transition model . Q-learning doesn’t. Instead of computing expected values over all possible transitions, the agent takes actions in the environment and updates its Q-values based on what actually happens.
The Q-values are stored in a Counter keyed by (state, action):
def __init__(self, **args):
ReinforcementAgent.__init__(self, **args)
self.values = util.Counter()
def getQValue(self, state, action):
return self.values[(state, action)]Counter defaults to 0, so any state-action pair the agent hasn’t visited yet has Q-value 0.
The value of a state is the max Q-value over available actions:
def computeValueFromQValues(self, state):
value = float('-inf')
for action in self.getLegalActions(state):
value = max(value, self.getQValue(state, action))
if value == float('-inf'):
return 0.0
return valueIf there are no legal actions (terminal state), value stays at negative infinity, so it returns 0.
Action selection with random tie-breaking:
def computeActionFromQValues(self, state):
legalActions=self.getLegalActions(state)
if not legalActions:
return None
else:
maxQValue = self.computeValueFromQValues(state)
actionList = []
for action in legalActions:
if maxQValue == self.getQValue(state, action):
actionList.append(action)
return random.choice(actionList)This collects all actions tied for the best Q-value and picks one at random. Without the tie-breaking, the agent would always pick the first action in the list, which biases exploration.
Epsilon-greedy exploration#
The agent needs to explore, not just exploit what it knows. Epsilon-greedy: with probability , pick a random action. Otherwise, pick the greedy best action.
def getAction(self, state):
legalActions = self.getLegalActions(state)
action = None
if util.flipCoin(self.epsilon):
action = random.choice(legalActions)
else:
action = self.computeActionFromQValues(state)
return actionutil.flipCoin(p) returns True with probability . When is high, the agent explores a lot. When it’s low, the agent mostly exploits.
The Q-learning update#
After the agent takes action in state , observes reward , and lands in state , the Q-value update is:
The term is the TD target: what the Q-value “should” be based on this one sample. The learning rate blends the old value with the new sample.
def update(self, state, action, nextState, reward):
previousValue = self.values[(state, action)]
presentValue = reward + (self.discount* self.computeValueFromQValues(nextState))
self.values[(state, action)] = ((1-self.alpha) * previousValue) + (self.alpha * presentValue)This is called after every step. Over many episodes, the Q-values converge to the true values (assuming every state-action pair is visited infinitely often, which epsilon-greedy guarantees as long as ).
The “not possible” question#
One question asked whether you could find epsilon and learning rate values that guarantee the Q-learning agent finds the optimal policy within 50 episodes on a bridge-crossing grid.
def question6():
answerEpsilon = None
answerLearningRate = None
return 'NOT POSSIBLE'The answer is no. 50 episodes is not enough to reliably learn the optimal policy on this grid. The bridge is long, and with epsilon-greedy exploration the agent needs many episodes to stumble across the bridge enough times to learn that the far side has a high reward. You can crank up epsilon to explore more, but then the agent’s policy is mostly random and it doesn’t exploit what it’s learned. You can lower epsilon, but then it rarely tries the bridge. There’s no setting that reliably works in just 50 episodes.
Approximate Q-learning#
Tabular Q-learning stores a value for every (state, action) pair. This doesn’t scale to large state spaces. Approximate Q-learning replaces the table with a linear function of features:
where are learned weights and are feature functions extracted from the state-action pair.
def getQValue(self, state, action):
qValue = 0
for feature,values in self.featExtractor.getFeatures(state, action).iteritems():
qValue += self.weights[feature]*values
return qValueThe weight update uses the same TD error, but applies it to each weight proportional to its feature value:
where is the TD error.
def update(self, state, action, nextState, reward):
presentValue = reward + (self.discount * self.computeValueFromQValues(nextState))
previousValue = self.getQValue(state,action)
for feature,value in self.featExtractor.getFeatures(state, action).iteritems():
self.weights[feature] += self.alpha*(presentValue-previousValue) * valueThe .iteritems() is a Python 2 thing (Python 3 would use .items()). The feature extractor returns a dictionary mapping feature names to feature values. The framework provides feature extractors for Pacman that pull out things like “distance to nearest ghost” and “distance to nearest food” as features. The agent just learns the weights.
The nice thing about approximate Q-learning is that the agent can generalize. If it learns that being close to a ghost is bad, that applies everywhere on the grid, not just in the specific cells it has visited. Tabular Q-learning can’t do that.