
Backprop by Hand and CNNs on MNIST
Hand-computing one step of backpropagation, then iterating on CNN architectures in MATLAB until giving up and switching to Keras.
Abstract#
The first part works through one step of backpropagation by hand on a small 2-layer network with known weights, computing the updated value of a single weight via the chain rule. The second part iterates on CNN architectures for MNIST digit classification. I spent hours trying to get deeper networks to train in MATLAB’s Deep Learning Toolbox before giving up and switching to Keras, where the same architecture that failed in MATLAB reached 99.73%.
This was the only assignment all semester where the starter code was MATLAB. I’d done every previous homework in Python (I was the first student in the class to do that), so being dropped back into MATLAB’s Deep Learning Toolbox was disorienting.
Part A: Backpropagation by hand#
Given a small 2-layer network with known weights, inputs, and a target. Goal: compute the updated value of after one step of gradient descent with learning rate .
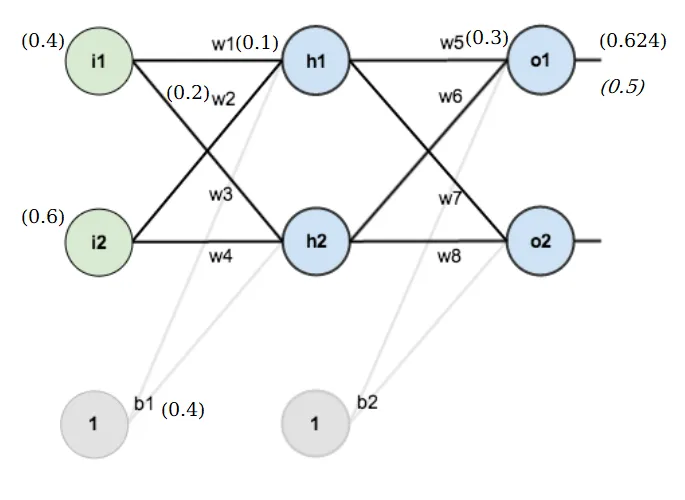
The chain rule gives us:
Three terms. Work through them one at a time.
Error gradient#
The error function is:
Only the first term depends on , so:
Sigmoid derivative#
The output comes from a sigmoid, so:
Partial with respect to #
So . But we need to compute from the input layer:
Therefore .
Weight update#
Multiply the three terms:
Apply gradient descent:
That’s it. On paper it’s mechanical. Doing it for a network with millions of parameters is why we have autograd.
Part B: CNN on MNIST#
The starter code (cnn.m) loads MATLAB’s built-in digit dataset (handwritten 0-9, split 50/50 train/test) and trains a simple architecture: one conv layer, ReLU, max pool, fully connected, softmax. 15 epochs. Out of the box it gets 96.76%.
The assignment was to modify the architecture to improve accuracy. We could only change the layer definitions and epoch count.
% Baseline layers (given)
Layers = [imageInputLayer([numRows numCols numChannels])
convolution2dLayer(3, 16)
reluLayer
maxPooling2dLayer(2, 'Stride', 2)
fullyConnectedLayer(numClasses)
softmaxLayer
classificationLayer()];Iterating in MATLAB#
I changed the filter size to 3 and filter count to 32. That got 96.96%. Then I added a fully connected layer of 128 nodes before the classifier and bumped batch size to 512. 97.98%. That was my best MATLAB result.
The obvious next step was adding more conv layers. I spent a lot of time trying to get this to work. MATLAB’s layer format kept rejecting my architectures, or the training would start and immediately flatline. I could see it in the console output: loss stuck at 2.3026 (which is , i.e. random chance for 10 classes), accuracy bouncing between 7% and 11%. The model was learning nothing.
Here’s a typical failed run. 43 minutes of training for 10.02% accuracy:
| 1 | 1 | 12.63 | 2.3026 | 7.81% | 1.00e-04 |
| 1 | 20 | 267.10 | 2.3025 | 10.94% | 1.00e-04 |
| 2 | 40 | 533.86 | 2.3025 | 7.81% | 1.00e-04 |
...
Elapsed Time: 43.19 minutes
Test Accuracy: 10.02%Another run: 12 minutes for 9.40%. Another: 24 minutes for 8.60%. The loss never moved from 2.30. I tried different layer orderings, different filter counts. Some configurations at least started learning (87.46%, 94.08%, 94.24%) but I couldn’t get past ~97% with more complex architectures. The models that worked were all basically the same shallow architecture with minor tweaks. Anything deeper just died.
I was also getting MEvent. CASE! spam in the console after every run, which I never figured out. Some MATLAB GUI event thing.
Giving up on MATLAB#
At some point I decided I’d wasted enough time fighting MATLAB’s layer API and rebuilt the model in Keras with a TensorFlow backend. The same shallow architecture gave a baseline of 95.48% in Keras (slightly lower, probably different initialization or data split randomization).
But in Keras I could actually stack conv layers without the model refusing to train. I built this:
- 2x Conv2D(64, 3x3) with ReLU
- MaxPool(2x2)
- 2x Conv2D(128, 3x3) with ReLU
- MaxPool(2x2)
- Dense(256) with ReLU
- Softmax output
99.73%. Almost three percentage points above my best MATLAB result, and the architecture took maybe ten minutes to write in Keras versus hours of dead ends in MATLAB.
The submission problem#
The assignment expected a .mat file with the trained model weights. I had Keras weights in .h5 format. I converted them using keras_converted.mat, but I had no idea if the grader’s MATLAB code would know how to load and run a Keras model from a .mat file. I submitted it separately and noted the situation in my writeup.
There’s something funny about this. I spent the entire semester doing everything in Python while everyone else used MATLAB. The one assignment that required MATLAB, I still ended up in Python for the best result. The MATLAB code is there, and it works (97.98% is fine). But 99.73% came from Keras.